基础训练--(07)JAVA与正规表示法(Regular Expression)
需要上课的人员:
试题1:
下图是台湾彩卷的大乐透资料,

网页的原始码为:
<tr>
<td colspan="3" class="td_org2">
大小顺序
</td>
<td class="td_w font_black14b_center">
<span id="SuperLotto638Control_history1_dlQuery_No1_0">14</span>
</td>
<td class="td_w font_black14b_center">
<span id="SuperLotto638Control_history1_dlQuery_No2_0">15</span>
</td>
<td class="td_w font_black14b_center">
<span id="SuperLotto638Control_history1_dlQuery_No3_0">19</span>
</td>
<td class="td_w font_black14b_center">
<span id="SuperLotto638Control_history1_dlQuery_No4_0">24</span>
</td>
<td class="td_w font_black14b_center">
<span id="SuperLotto638Control_history1_dlQuery_No5_0">25</span>
</td>
<td class="td_w font_black14b_center">
<span id="SuperLotto638Control_history1_dlQuery_No6_0">37</span>
</td>
<td colspan="2" class="td_w font_red14b_center">
<span id="SuperLotto638Control_history1_dlQuery_No7_0">06</span>
</td>
</tr>
JAVA程式码如下:
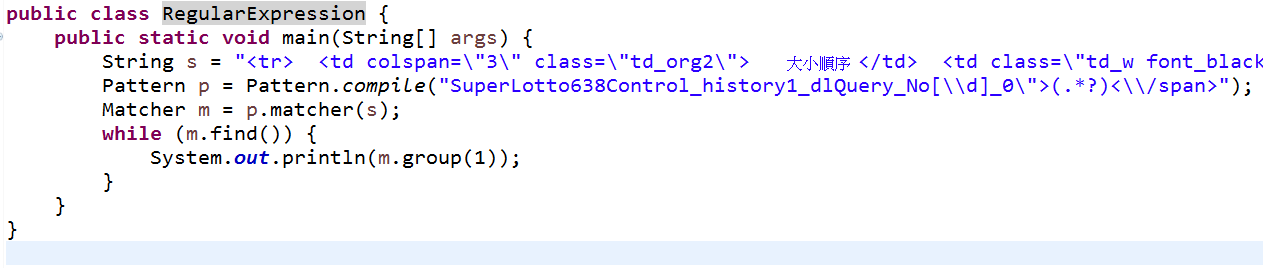
请问Pattern.compile(" ")中的双引号内号该填什么,才能得到本期开奖数字?
答案:SuperLotto638Control_history1_dlQuery_No[\d]_0">(.*?)<\/span>(反白中)
答案可能不止一种,可至线上的正规表示法测试网站测试。
正规表示法(Regular Expression)
正规表示法(或称正规表示式)是一个很强大的工具,它的功能是快速的过滤出符合特定规则的文字,并回传给使用者,所以会有二段字串,一段是要我们要寻找的特定文字,一段是要被寻找的文字,而我们要寻找的特定文字,就是我们待会要讲的正规表示式。
常用的正规表示法的特殊字元
正规表示式虽然很强大,不过因为它不好懂,而且有太多的特殊字元,每个字元又有不同的意义,所以在入门时比较不好入门;不过,要学正规表示法,并没有其他捷径,所以我们不能免俗的要介绍这些特殊字元,下方是笔者个人记得的特殊字元与其对应的功能,既然是笔者个人记得的,代表在工作上是比较被使用的,我们一一来介绍:
-
^ →Shift + 6
这个符号有三种意义,分别是「开始」与「不符合」及代符号^本身;判断是那一种意义,要视摆放的位置而定,下方为范例:
-
^abc → 代表文字开头为abc,即时^的意义为「开始」。
-
[^abc] → [ ]的意义为字元,代表这个字元必需符为[ ]内的字元,不过在[ ]里面的^代表的是「不符合」,所以[^abc]代表这个字元必须不符合abc才行。
-
ab^c → 此时的^并没有特别的意义。
-
* → Shift + 8
这个大家比较常用,所以很好理解,这是代表任意字元的意思,而且包含0~N个字元。
-
$ → Shift +4
这个代表每一行结尾,通常在$前方会搭配一段文字,例如:Excetpion$,代表我们要寻找该行以Exception结尾的地方。
-
[ ] → 中括号
[ ]括号中的内容代表一个字元,例如[abc],代表这个字元可以是a或b或c。
-
- →减号
这个符号必须被使用[ ]中, 代表连续的文字,其中连续的意义是以ASCII码来计算的,例如:[0-9]代表字元可以是0到9、[a-zA-Z]代表字元可以是小写a到z及大写的A到Z。
-
\ → 跳脱字元
如果我们想寻找某些特殊字元,而不是它们代表的特殊意义,即需要用\来放在特殊字元的前方,例如:\*,代表*这个符号本身,而非任意字元。
-
\d → 跳脱字元+d
代表的是数字,等同[0-9]。
-
\w → 跳脱字元+w
代表文字,即[0-9a-zA-z_],注意:_(底线)也包含在其中。
-
\W → 跳脱字元+W
代表非文字,即[^0-9a-zA-z_]。
-
\s → 跳脱字元+s
会产生空白的字元也就是 [ \t\n\x0B\f\r],也就是 " "(空白)、"\t"、"\n"、"\x0B"、"\f"、"\r"。
-
( ) → 小括号
代表我们想要抓取的文字,例如:"(.*?)",代表我们想要抓取" "中的文字,后方会做更详细的介绍。
其他还有很多,不过上方是笔者记得的,也就是常用的,如果要详细研读,建议可以在Google找资料。
JAVA中实作正规表示法
大概了解正规表示法的运作后,接来下我们要实际在JAVA中来使用它,要在JAVA使用正规表示法,必须使用java.util.regex.Pattern这个Class,如上方的题目所示:
Pattern.compile内接正规表示式,而利用Pattern中的matcher Method来实作正规表示法,例如:
执行后的结果:

在这个范例中,我们来看( )这个小括号对应的用法,程式码为:

首先,Matcher m是从Pattern的matcher来的,传入参数s为要比对的字串;再来利用m.find()来判断是否有找到对应的内容,以本例来说:

配合
这一个正规表示式,在第一次的find时,会找到下方红框处:

而m.group(0)会回传:
SuperLotto638Control_history1_dlQuery_No1_0">14</span>
m.group(1)会回传:
14
而第二次的while回圈会抓到下方的红框处:

一样,在while中的m.group(0)会回传:
SuperLotto638Control_history1_dlQuery_No1_0">15</span>
m.group(1)会回传:
15
这个就是Matcher的group用法。
作业
请选定某个网页,并取得网页中所有的input标签的name与value的值。
参考网址:https://www.javaworld.com.tw/jute/post/view?bid=20&id=130126







